아래는 PA201 연구의 구성원입니다. BCD 이 글을 쓴 사람은
데이터 분석이 어렵습니다. 상관관계, 회귀분석, 의사결정나무 등 어려운 분석은 어디에나 있습니다. 무슨말인지 모르시더라도.. 기초통계도 사람수 세는것도 어려운데.. 그래서 용기를 내서 데이터 분석을 합니다. 배짱으로 시작해서 배짱으로 끝난다. 더 이상 가능하지 않을 때까지… 그것이 데이터 분석에 관한 제 신조입니다.
이 이야기를 하는 이유는 무엇입니까? 이렇게 어렵고 힘든 분석이 다른 사람에게는 매우 쉽게 보일 수 있기 때문입니다. 특히 엑셀 소설을 잘 다루지 못한 사람들은 회사의 재직자 수와 신입사원 수를 대략적으로 추정한다. 타닥! 하다보면 나온다는 걸 알 수 있습니다.
팀 리더 배우 비씨디~ 아침에 만나요 지난 n년 부서별 신입사원/사원/퇴사자 수의 변화붓다 월간 간행물저에게 신고하세요.”
BCD 대리인 “아침까지…?
팀 리더 “피벗 돌리면 나온다~”
화가 나지만 팀장을 원망할 수는 없다. 내가 피벗을 돌리면 나오는 걸 상사가 아닌 다른 사람이 알기 때문이다… 그래서 이번에 다시 용기를 내본다.
인원수를 계산하려면 어떤 데이터가 필요합니까?
인사팀장은 일자를 선택할 때 인사시스템(ERP 등)에 ‘마감일’을 설정하고 그 일자를 기준으로 리스트를 선택한다. 이때 제도의 종류에 따라 재직자/퇴직자를 별도로 조회해야 하는 경우가 있습니다.
참조 날짜가 필요한 이유는 무엇입니까? 직원의 직위와 부서는 기준일(최종임용)에 따라 달라지기 때문입니다.

따라서 특정 날짜(예: 2023년 1월 31일)를 검색하면 해당 날짜의 직위와 부서만 표시되므로 지난 10년간 부서별 직원 수를 확인할 수 없습니다. 나타나다!
그럼 어떻게 해결해야 할까요? 두 가지 옵션이 있습니다(아니, 실제로는 하나만).
첫 번째 방법은 약속 데이터를 가져와 직원 목록과 비교하는 것입니다. 특정 기본 날짜를 무작위화하고 가장 최근에 일치하는 날짜를 얻을 수 있습니다. (엑셀로 해도 되지만, 데이터가 많을 때는 어렵습니다.)
두 번째 방법은 실무자가 지속적으로 검색하고 저장하고, 검색하고 저장하고, 검색하고 저장하고, 매월 말일(또는 첫날)에 검색하고 저장하고 마지막에 모든 파일을 병합하는 것입니다. 너무 쉬워 보인다. 하지만 실제로 그렇게 하려면 많은 용기가 필요합니다. 첫째, 검색 및 저장이 예상보다 오래 걸리며 병합하려면 각 파일에 대한 검색 날짜 열을 만들어야 합니다.
그래서 처음부터 길은 하나뿐이라고 말한 것이다. 정말 많은 양의 데이터의 경우 두 번째 방법은 쓸모가 없습니다. 모든 데이터는 “표준 정보”, “약속”, “주인 정보” 등으로 구성되어 있기 때문에 첫 번째 방법으로 전체 조회 약속 목록을 체계적으로 생성할 수 있으며 두 번째 방법은 필요하지 않습니다.
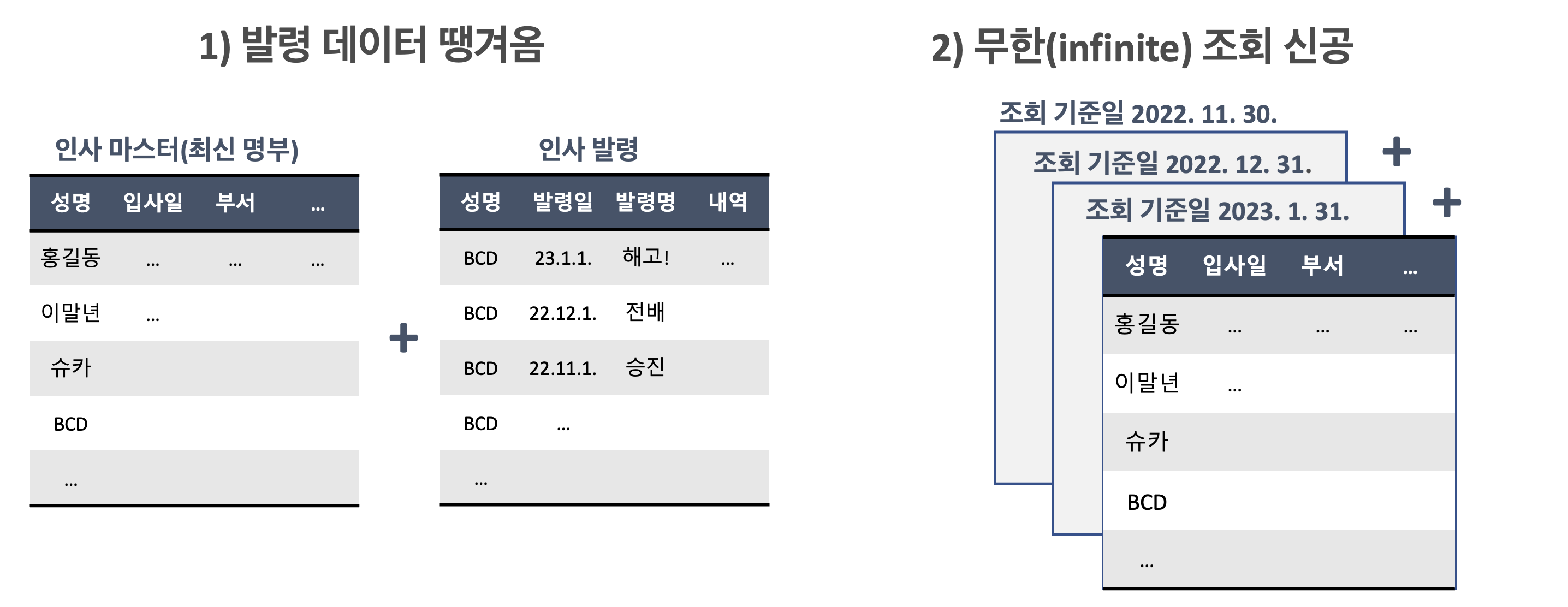
뭐 어쨌든 이런저런 방법을 이용해서 최종적으로 아래와 같이 패널 데이터를 구성할 수 있습니다.
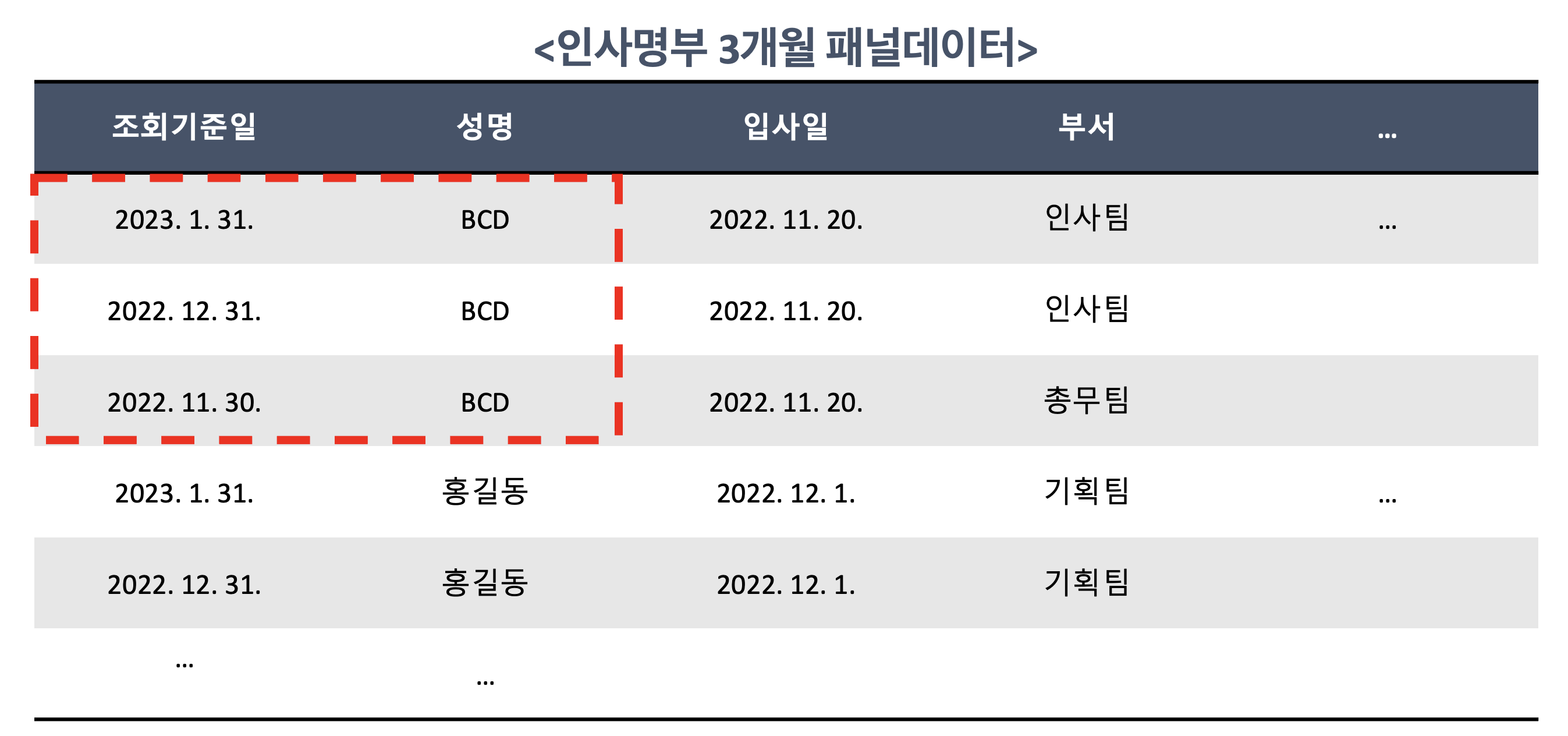
여기서 주목할 점은 신입사원 및 재직자 수뿐만 아니라 퇴직자 수를 결정해야 하므로 위 n기간 동안 퇴직자를 직원 명단에 포함시킬 필요가 있다는 점이다. 단, 퇴직한 근로자는 퇴직월까지만 입국하면 됩니다. 예를 들어, 23년 1월 20일에 은퇴하면 23년 1월 31일, 22년 12월 31일의 기준 날짜로 목록에 포함되지만 2023년 2월 28일 목록에는 포함되지 않습니다!
(연습) 인원수를 정하자!
이렇게 데이터를 구성했다면 지난 N년부서별신입사원/사원/퇴사자 수의 변화 저장 준비 됐어 이제 인터넷에 떠도는 데이터로 연습하자고 생각했는데… 인터넷에 떠도는 데이터는 패널 형태의 HR 데이터가 아니라 특정 시점에만 존재했던 데이터 여러 기간.
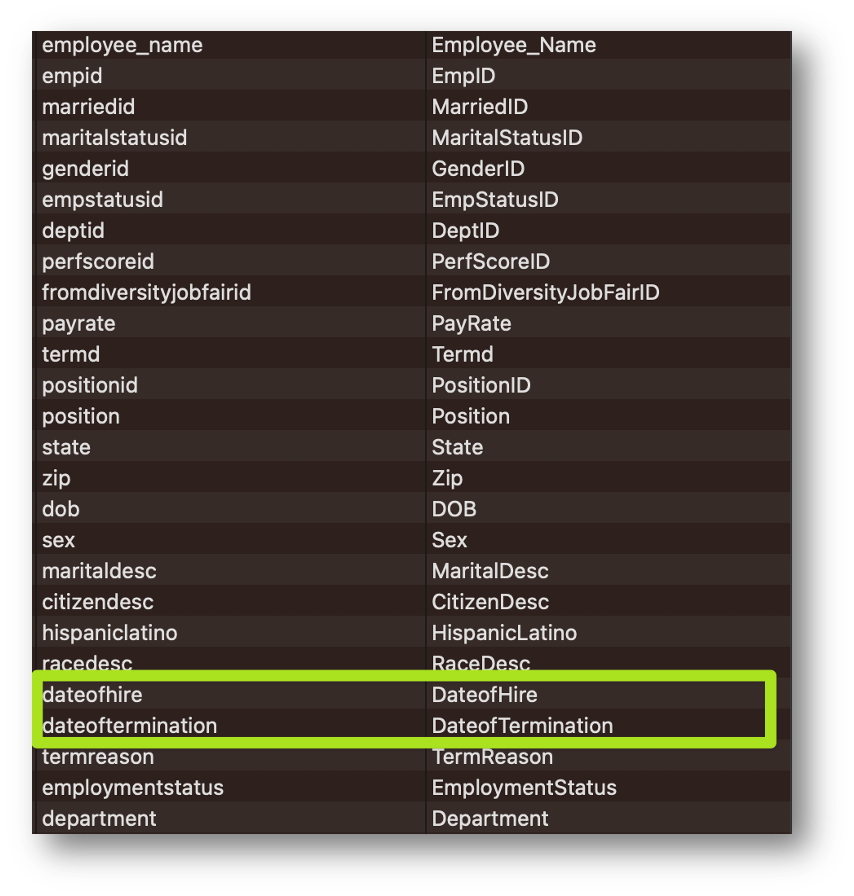
좋아요! 그러니 용감하게 스스로 데이터를 만들어 봅시다.
이 데이터에는 각 개인의 입사 및 퇴사 날짜가 포함됩니다.
R로 전처리 및 시각화를 위해 Stata를 사용할 계획입니다.
Stata는 경제학 분야의 많은 괴짜(또는 숙녀)가 사용하는 통계 도구이지만 간단하고 직관적이기 때문에 제가 좋아하는 프로그램입니다.
1. 데이터 불러오기 및 부서 랜덤 매칭

복잡해 보이지만 실제로는 특별한 것이 아닙니다.
나는 단순히 데이터를 가져오고, 필요한 변수를 추출하고, 날짜 변수를 날짜 형식으로 지정하고, 부서를 내가 좋아하는 다섯 가지에 일치시켰다.
여기서 부서는 1에서 5 사이의 숫자를 동일한 확률로 무작위로 매칭하고 각 숫자를 인사팀, 재무팀, 기획팀, 구매팀, 혁신팀으로 명명합니다.
2. 월별 데이터 저장 및 패널 데이터셋 생성

그 후 모든 날짜는 월별로 루프에 저장될 수 있습니다.저의 경우 루프 문을 사용하여 기본 날짜를 만들고 입력 날짜가 기본 날짜(?)보다 크면 행을 삭제하고 만료 날짜이면 행을 삭제합니다. 기준일과 같거나 작습니다. 이 경우에는 기본 날짜를 매월 말일로 사용했는데, 이는 흥미롭습니다. 먼저 모든 달의 첫 번째 날(1일)로 날짜를 만들고 마지막 날에 1달을 더하고 1일을 빼서 날짜를 만들었다. 이 방법으로 다음과 같은 여러 파일을 만들었습니다.

그런 다음 월별 인원을 결합하여 긴 형식으로 데이터를 추가하고 마지막으로 은퇴자 목록을 병합했습니다.
퇴직 날짜가 모든 마지막 날과 같거나 이전인 경우를 이미 모두 삭제했기 때문에 이번 달 목록에 퇴직자가 없습니다. 기준일과 퇴직일이 같으면 그 달에 퇴직한 사람을 1명으로 계산해야 하기 때문에 이렇게 두었습니다.
그리고 기준일이 입사일 또는 퇴사일과 동일한지 비교하여 “현재 근무월”, “현재 입사월”, “현재 퇴직월” 등을 구하여 최종 데이터셋을 생성한다. . 예를 들어, 현 임기의 경우 입사일이 기준일 이전이고 퇴직일이 기준일 이후이면 1, 그렇지 않으면 0으로 코딩한다.

3. 신입사원, 재직자, 퇴직자 월별/부서별 인구조사
여기까지 오면 정말 끝이다. 이제 피벗을 대략적으로 돌리면 집계된 숫자가 표시됩니다. 기준일 또는 기준일/부서에 대한 그룹으로 “현재 고용”, “현재 입사” 및 “현재 퇴직”의 합계를 찾기만 하면 됩니다!

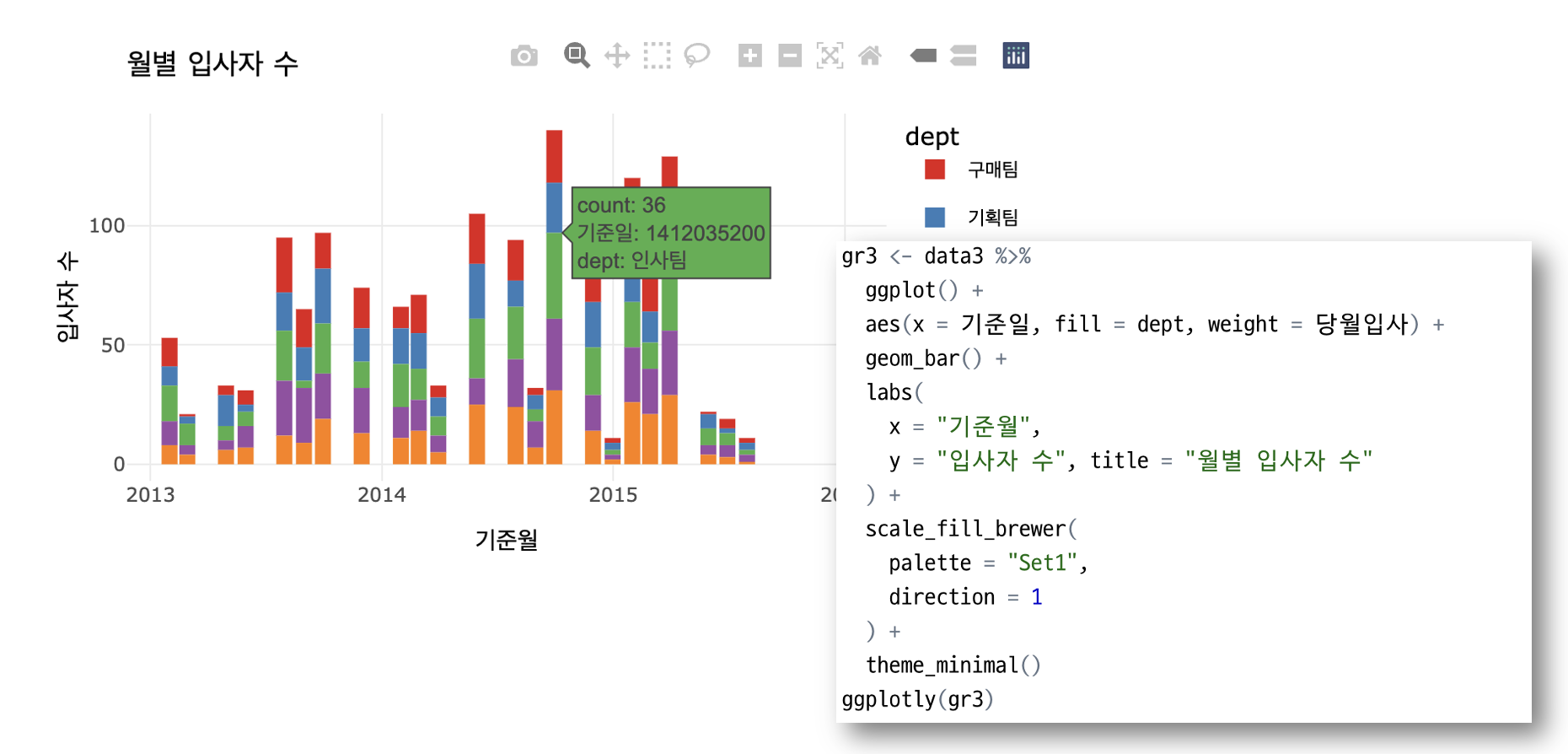
4. 시각화
시각화를 위해 집계를 Excel에 저장한 다음 R로 가져왔습니다. 나는 R을 정말 서투르지만 R을 잘하는 많은 전문가들이 나와 같은 사람들을 위해 매우 편리하게 시각화할 수 있는 패키지를 만들었습니다. 그들은 ggplot, plotly 및 esquisse입니다.
다음으로 패키지에 대해 조금 더 설명드리도록 하겠습니다… 먼저 위의 데이터셋을 이용하여 간단히 시각화 해보았습니다. 결과는 아래와 같습니다.
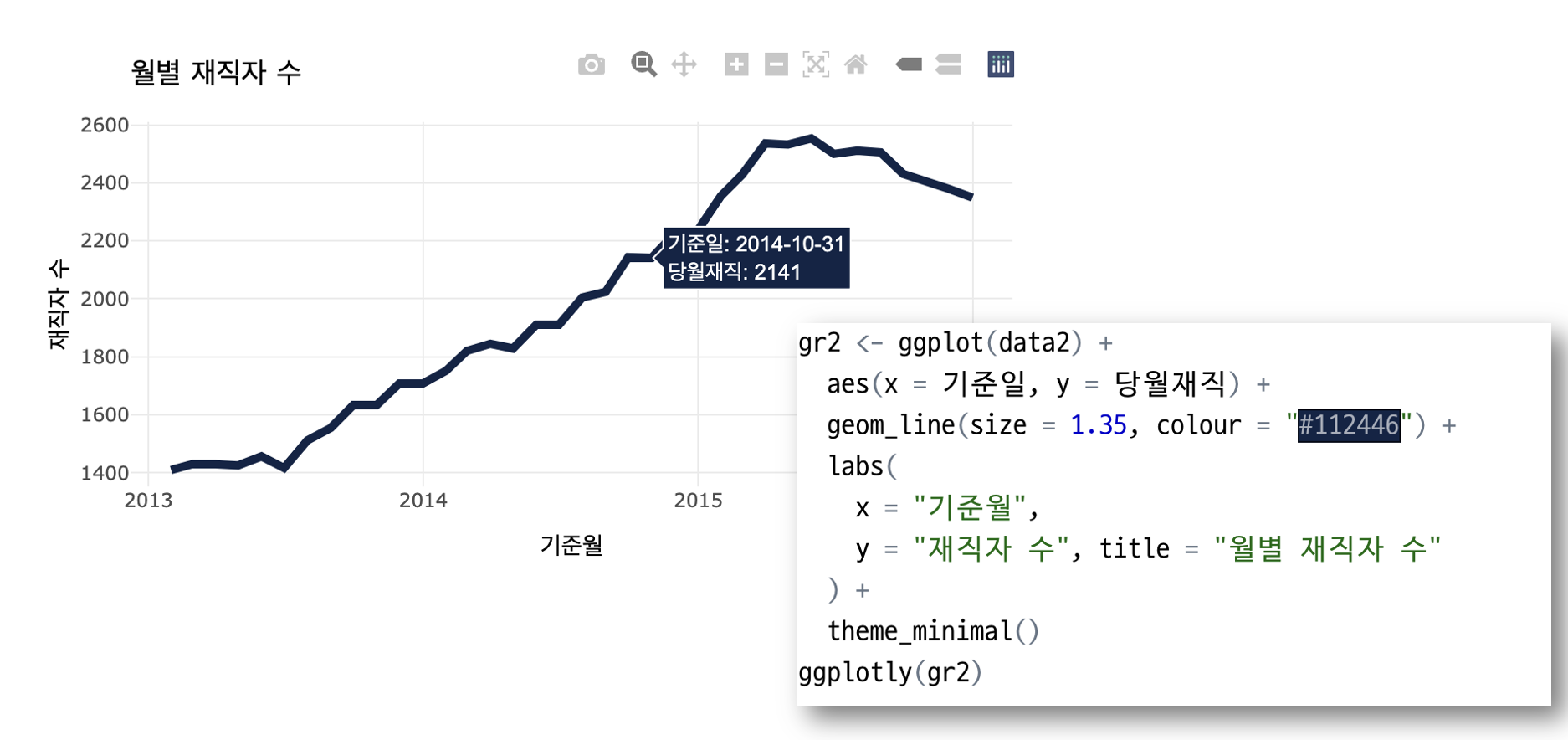
BCD 대리인 “관리자, 지난 n년부서별신입사원/사원/퇴사자 수의 변화붓다월간 간행물보고될 것이다“
끝…
새삼 느끼지만 세상에 쉬운 일은 없다.